

Share article:
Tags:
Toby Smith | Machine Learning Engineer, Mindtech Global
In object detection tasks, false positives — incorrectly identified objects — are often seen as obstacles. However, these false positives can provide valuable insights into what the model is getting wrong and what needs to be improved in the training dataset. Manually sorting through potentially thousands of false positive images is not only time-consuming but also inefficient. Clustering techniques offer a solution by grouping similar false positives together, making it easier to decide which objects should be added to the simulation. This blog post explores the use of various clustering techniques to categorize false positives, using the A2D2 Audi dataset as a case study.
Data Preparation
The false positive images used in this analysis were generated by a YOLOv8 model trained exclusively on synthetic data provided by the Mindtech Chameleon simulator. Synthetic data can be a powerful tool for training object detection models due to its ability to generate a vast number of labelled images efficiently. However, when these models are deployed in real-world scenarios, they often encounter objects and scenes that were not fully represented in the training data, leading to false positives.
To evaluate the performance of the model in a real-world setting, we ran inference on the Audi A2D2 dataset, a comprehensive collection of real-world driving images. This dataset includes a variety of challenging urban environments, making it an ideal test bed for assessing the robustness of our YOLOv8 model. The inference process identified a large number of false positives — objects that the model mistakenly identified as relevant but are actually not present in the scene. These false positives are the focus of our clustering analysis, as they highlight the gaps between the training data and real-world environment.
ResNet50 and K-Means Clustering
Our initial approach involved using ResNet50, a well-established convolutional neural network, as a feature extractor. ResNet50’s ability to classify images based on content rather than raw pixels makes it a suitable choice for generating feature vectors from false positive images. These feature vectors, which are essentially summaries of the image content, were then fed into the K-means clustering algorithm.
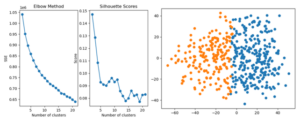
Challenges with K-Means
K-means clustering requires the number of clusters (k) to be predetermined. To estimate the optimal number of clusters, we used the Elbow method, which plots the variance explained by each cluster number to find an “elbow” point where adding more clusters does not significantly improve the model. However, this approach did not yield clear results. The lack of a distinct elbow in the graph suggested that the data was too noisy, making it difficult to identify meaningful clusters. Additionally, the silhouette scores — a metric for evaluating the quality of clusters — indicated that the data was best represented by only two clusters, which was not informative.
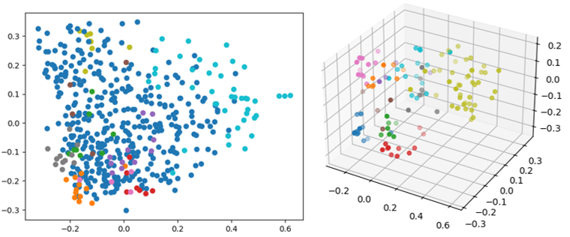
Inception V3 and HDBSCAN
Given the limitations of K-means, we turned to a more advanced clustering algorithm: HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise). Unlike K-means, HDBSCAN does not require specifying the number of clusters. Instead, it identifies clusters based on the density of data points, making it better suited for noisy and complex datasets like ours.
To further enhance the clustering process, we replaced ResNet50 with Inception V3 as the feature extractor. Inception V3, another powerful convolutional neural network, provided a different perspective on the data, generating feature vectors that led to more distinct and meaningful clusters. This change in feature extraction helped identify additional clusters, including those containing bicycles or bushes, which were not as evident with ResNet50.
CLIP + UMAP and HDBSCAN
Recognizing that the choice of feature extraction method is crucial, we explored the use of CLIP (Contrastive Language–Image Pretraining) by OpenAI, a modern image-text embedding model. CLIP’s ability to embed images in a feature space that aligns with textual descriptions offered a new way to approach the clustering task.
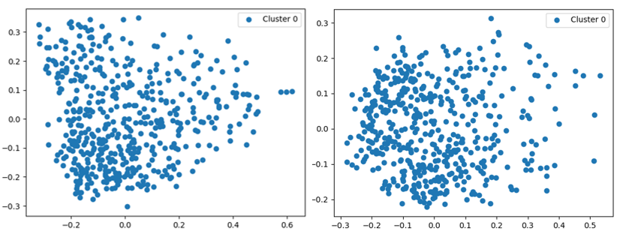
In addition to using CLIP, we incorporated UMAP (Uniform Manifold Approximation and Projection), a non-linear dimensionality reduction technique. UMAP is particularly effective at preserving the local structure of the data, making it ideal for clustering tasks. By combining CLIP’s powerful feature extraction with UMAP’s dimensionality reduction, we were able to create a more refined feature space where HDBSCAN could more easily identify dense clusters.
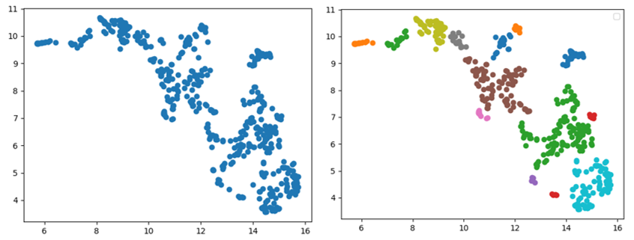
Final Clustering Results
After tuning both UMAP and HDBSCAN parameters, the final clusters were much more informative. The resulting clusters successfully grouped false positives into distinct categories, such as traffic lights, road signs, small distant vehicles, and other unannotated objects. These clusters provided clear guidance on what should be added to the training dataset to improve the model’s performance.
Conclusion
Clustering false positive images using advanced techniques like, CLIP, UMAP, and HDBSCAN offers a powerful approach to refining object detection models. By moving beyond simple pixel-based clustering and leveraging sophisticated feature extraction and dimensionality reduction methods, we can better understand the types of objects that cause false positives and take targeted action to reduce them. This process not only streamlines the analysis of false positives but also leads to more accurate and robust object detection models, especially when training with synthetic data.

To find out more about using synthetic data for training real-world models, click here.
Clustering of False Positives to Improve Object Detection Training Data: Part 1 was originally published in MindtechGlobal on Medium, where people are continuing the conversation by highlighting and responding to this story.





